Performance testing in CI: Let's break the build!

Raise your hand if you've ever poured countless hours into making a fast website, only to have it slowly degrade over time. New features, tweaks, and Super Important Tracking Snippets all pile up and slow things down. At some point you'll be given permission to "focus on performance" and after many more hours, the website will be fast again. But a few months later, things start to slow again. The cycle repeats.
What if there was a way that you could prevent performance from degrading in the first place? Some sort of performance gateway that only allows changes to production code if they meet performance requirements? I think it's time we talked about having performance regressions break the build.
The secret to a faster website? Break the build!
If "breaking the build" is a foreign concept to you, then allow me to explain. Continuous integration ("CI") is a stepping stone on the journey to streamlined software delivery. With sufficient automated testing, you can have a high level of confidence that an isolated change can be built and integrated without breaking anything else. If any of the automated tests fail, then the build is broken and the change cannot be integrated.
This concept can be extended even further by automatically deploying changes to testing or staging environments (continuous delivery), running more automated tests, and potentially even deploying the change to a production environment with zero human input (continuous deployment).
Performance as acceptance criteria
When automated testing is talked about in the context of CI, it almost exclusively refers to functional testing - testing whether a feature functions as expected. Performance typically doesn't impact the functionality of a feature, so it is often absent from the list of acceptance criteria. However, if our goal is to prevent performance regressions then performance must become a non-functional requirement in our acceptance criteria. We want to be able to break the build and block a change from being shipped if its performance is not up to standard.
Where performance fits in a CI pipeline
So where in a CI/CD pipeline do we put performance testing? The easy answer is: right after a change is deployed to an integration or testing environment. Typically, performance testing should happen at the same time as integration and acceptance testing. The slightly more complex answer is: it depends. For performance testing to be accurate, the integration environment should replicate the production environment as closely as possible. Here's a short (and definitely not exhaustive) list of things that you may want to consider when running performance tests on an integration environment:
- Caches may need to be warmed up beforehand. Production environments typically have high cache hit ratios, and this should be replicated during performance testing.
- If system resources are a constraint, it may be better to run performance testing in isolation. Running it at the same time as integration testing or load testing could cause resource contention that negatively affects performance.
- Network latency will affect performance testing. If your production environment is accessed via a CDN, try to run your integration environment through the same CDN.
Performance in CI without breaking the build
I know, I know. The title of this post says that to be fast you have to break the build! The reality is that many software delivery teams are not in a position to do this. Most stakeholders that I've worked with would find it unacceptable to block an important feature or bug fix due to it failing performance tests.
Thankfully, there are some other options. Let's go through them, starting with the holy grail: staying fast by breaking the build.
Break the build on performance regressions
The build is blocked until performance testing completes, and can potentially fail if any performance tests fail. This option only works in teams that have 100% buy-in from all levels, since they will need to fix performance issues before they can continue with any other work.
Pros
- Treats performance as a first-class acceptance criteria.
- Creates a complete feedback loop for teams to manage the performance of their work.
- Performance regressions are caught before they make it to production.
Cons
- Increases build time.
- Requires buy-in from the whole team.
Report performance regressions but do not break the build
The build can be blocked until performance testing completes, but this is not mandatory. Any performance test failures are reported but do not fail the build. This option works well in teams with a strong performance culture who take performance regressions seriously. Performance issues won't block the build and delay important work, but they will be treated as a high priority and addressed in a timely manner.
Pros
- Provides actionable feedback loop for teams to fix performance regressions.
- Performance regressions can be caught before production.
- Doesn't block things from being pushed to production.
Cons
- Requires strong discipline to prevent performance regressions.
Trigger performance tests without any reporting
Performance tests are triggered as part of the build but do not block anything. This option is good for teams who are just starting to monitor performance, or who prefer to have regular "performance sprints" rather than fix regressions as they occur.
Pros
- Can be used to retrospectively identify the build that caused a performance regression.
- Doesn't require any buy-in from team members.
- Can be easily transformed into other options later.
Cons
- Requires strong discipline to prevent performance regressions.
- Makes it easy to consider performance as a "nice to have" feature or forget about it entirely.
Using the SpeedCurve CLI to monitor performance
SpeedCurve recently released an official CLI and Node.js API that simplifies running performance tests as part of a CI/CD pipeline. I'll put some example commands below to give you an idea of how it can be used.
# Option 1: Break the build on performance regressions.
# Runs performance tests and waits until they finish. Upon completion, checks the
# status of any performance budgets and exits with a non-zero exit code if any
# budgets were broken.
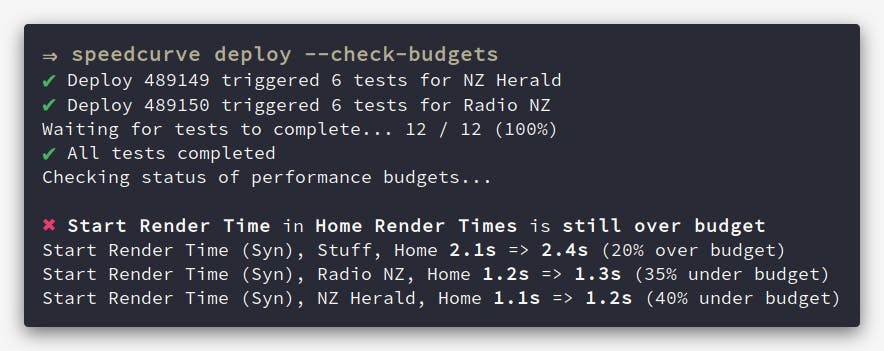
speedcurve deploy --check-budgets
# Option 2: Report performance regressions but do not break the build.
# Runs performance tests and waits until they finish. Then uses the "budgets"
# command to output the status of all performance budgets as JSON.
speedcurve deploy --wait
speedcurve budgets --json
# Option 3: Trigger performance tests without any reporting.
# Runs performance tests but does not wait for them to finish. The --note flag
# annotates the deploy in SpeedCurve so that this build can be identified when
# reviewing performance regressions at a later date.
speedcurve deploy --note v2.48.0-b28bc40If you'd like to try out the SpeedCurve CLI for yourself, head on over to the GitHub project for installation instructions and usage examples. If you don't already have a SpeedCurve account, you can start a free trial and begin testing your pages within minutes.